
In a earlier put up, I described a sharding formula to scale throughput and function for question and ingest workloads. On this put up, I can introduce any other not unusual methodology, partitioning, that gives additional benefits in functionality and control for a sharding database. I can additionally describe tips on how to deal with walls successfully for each question and ingest workloads, and tips on how to arrange chilly (outdated) walls the place the learn necessities are rather other from the new (contemporary) walls.
Sharding vs. partitioning
Sharding is a strategy to cut up information in a allotted database formula. Information in every shard does no longer need to proportion assets similar to CPU or reminiscence, and may also be learn or written in parallel.
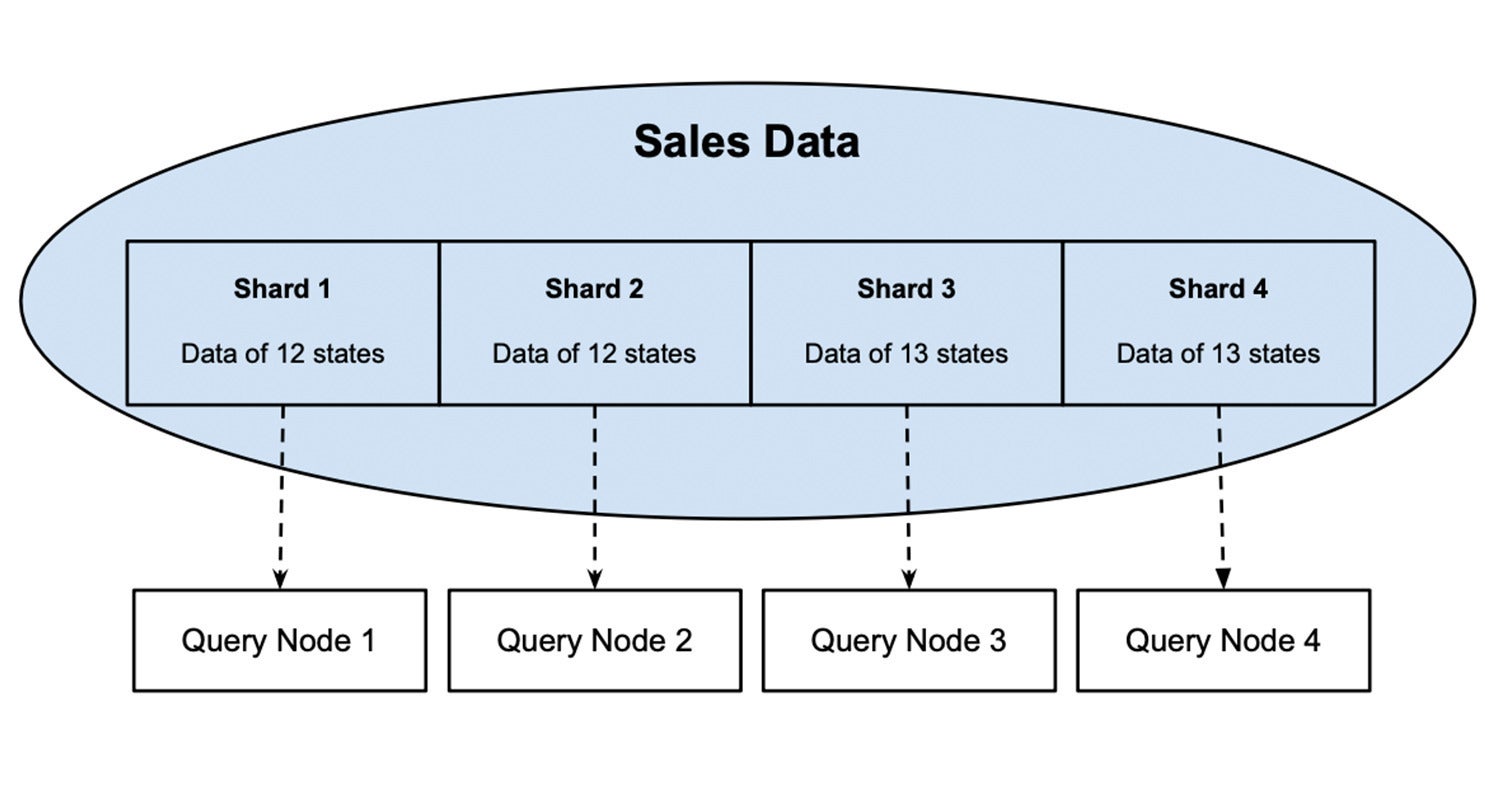
Determine 1 is an instance of a sharding database. Gross sales information of fifty states of a rustic are cut up into 4 shards, every containing information of 12 or 13 states. By way of assigning a question node to every shard, a task that reads all 50 states may also be cut up between those 4 nodes working in parallel and will likely be carried out 4 instances quicker in comparison to the setup that reads all 50 states via one node. Extra details about shards and their scaling results on ingest and question workloads may also be present in my earlier put up.
 InfluxData
InfluxDataDetermine 1: Gross sales Information is divided into 4 shards, every assigned to a question node.
Partitioning is a strategy to cut up information inside of every shard into non-overlapping walls for additional parallel dealing with. This reduces the studying of useless information, and lets in for successfully imposing information retention insurance policies.
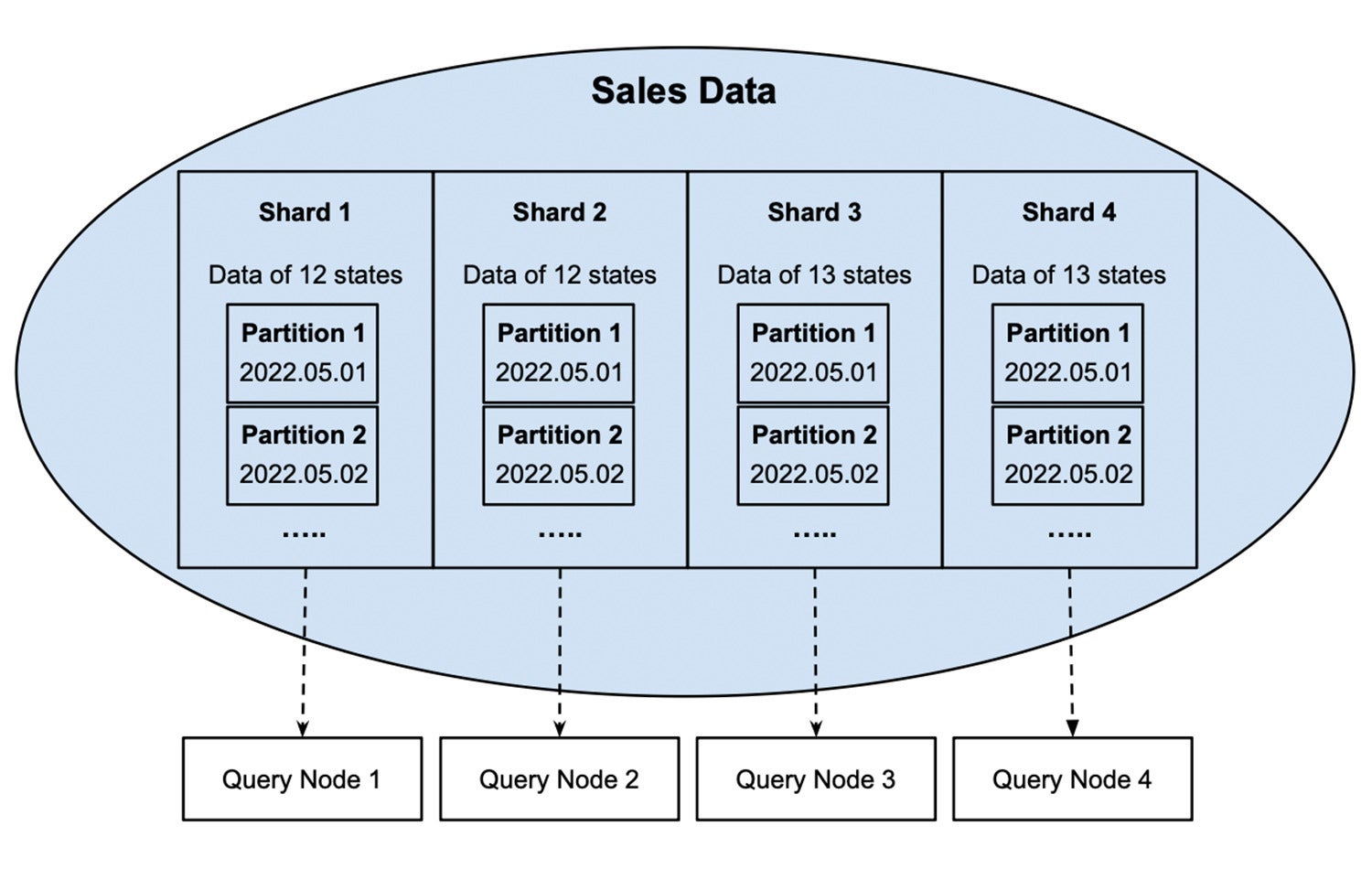
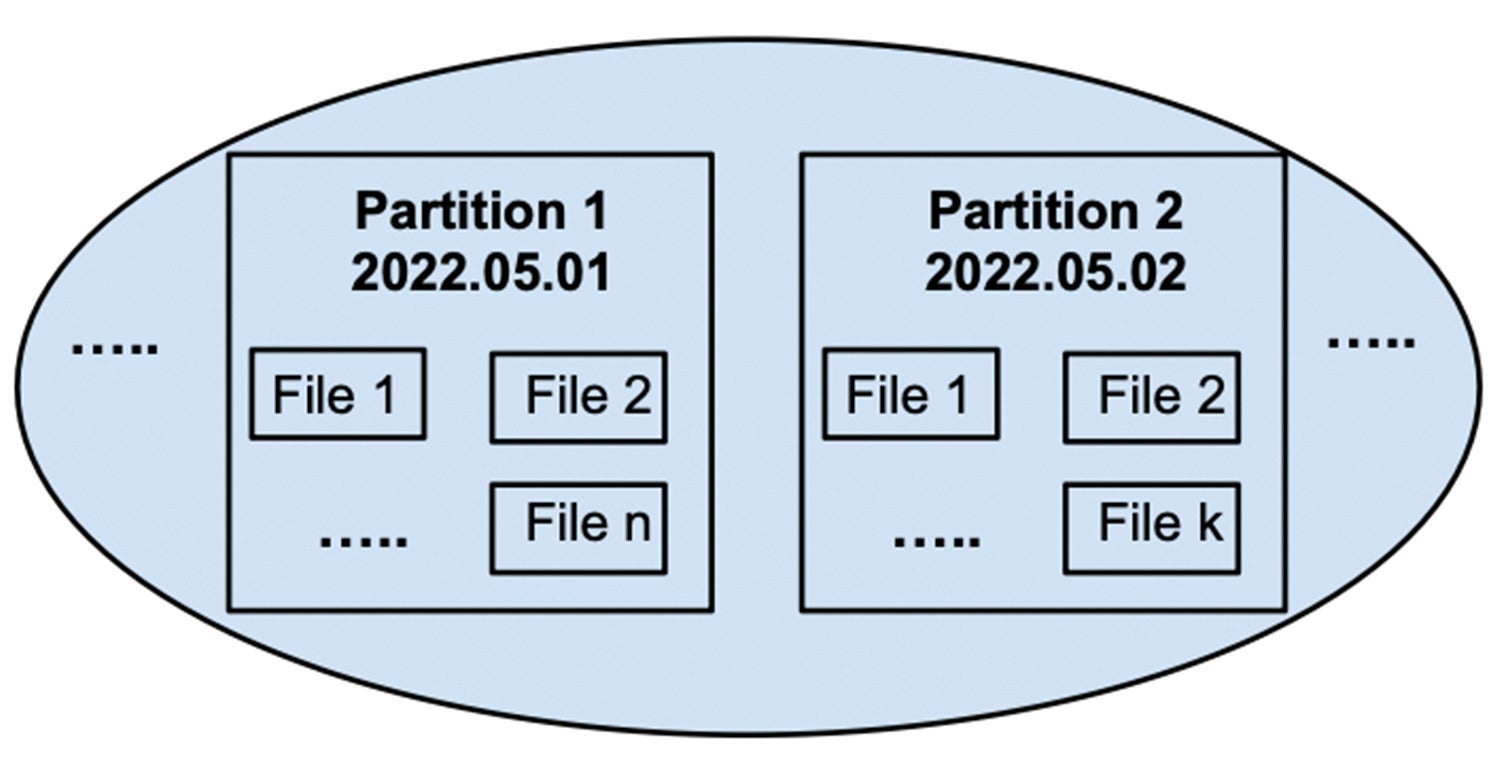
In Determine 2, the information of every shard is partitioned via gross sales day. If we wish to create a document on gross sales of 1 explicit day similar to Might 1, 2022, the question nodes most effective wish to learn information in their corresponding walls of 2022.05.01.
 InfluxData
InfluxDataDetermine 2: Gross sales information of every shard is additional cut up into non-overlapped day walls.
The remainder of this put up will focal point at the results of partitioning. We’ll see tips on how to arrange walls successfully for each question and ingest workloads on each cold and warm information.
Partitioning results
The 3 maximum not unusual advantages of knowledge partitioning are information pruning, intra-node parallelism, and rapid deletion.
Information pruning
A database formula might include a number of years of knowledge, however maximum queries wish to learn most effective contemporary information (e.g., “What number of orders were positioned within the remaining 3 days?”). Partitioning information into non-overlapping walls, as illustrated in Determine 2, makes it simple to skip whole out-of-bound walls and browse and procedure most effective related and really small units of knowledge to go back effects briefly.
Intra-node parallelism
Multithreaded processing and streaming information are important in a database formula to totally use to be had CPU and reminiscence and acquire the most productive functionality conceivable. Partitioning information into small walls makes it more uncomplicated to put into effect a multithreaded engine that executes one thread consistent with partition. For every partition, extra threads may also be spawned to deal with information inside of that partition. Figuring out partition statistics similar to measurement and row depend will lend a hand allocate the optimum quantity of CPU and reminiscence for explicit walls.
Rapid information deletion
Many organizations stay most effective contemporary information (e.g., information of the remaining 3 months) and need to take away outdated information ASAP. By way of partitioning information on non-overlapping time home windows, casting off outdated walls turns into so simple as deleting information, with out the wish to reorganize information and interrupt different question or ingest actions. If all information will have to be saved, a bit later on this put up will describe tips on how to arrange contemporary and outdated information otherwise to make sure the techniques supply nice functionality in all circumstances.
Storing and managing walls
Optimizing for question workloads
A partition already comprises a small set of knowledge, so we don’t need to retailer a partition in lots of smaller information (or chunks in relation to in-memory database). A partition will have to include only one or a couple of information.
Minimizing the choice of information in a partition has two essential advantages. It each reduces I/O operations whilst studying information for executing a question, and it improves information encoding/compression. Bettering encoding in flip lowers garage prices and, extra importantly, improves question execution velocity via studying much less information.
Optimizing for ingest workloads
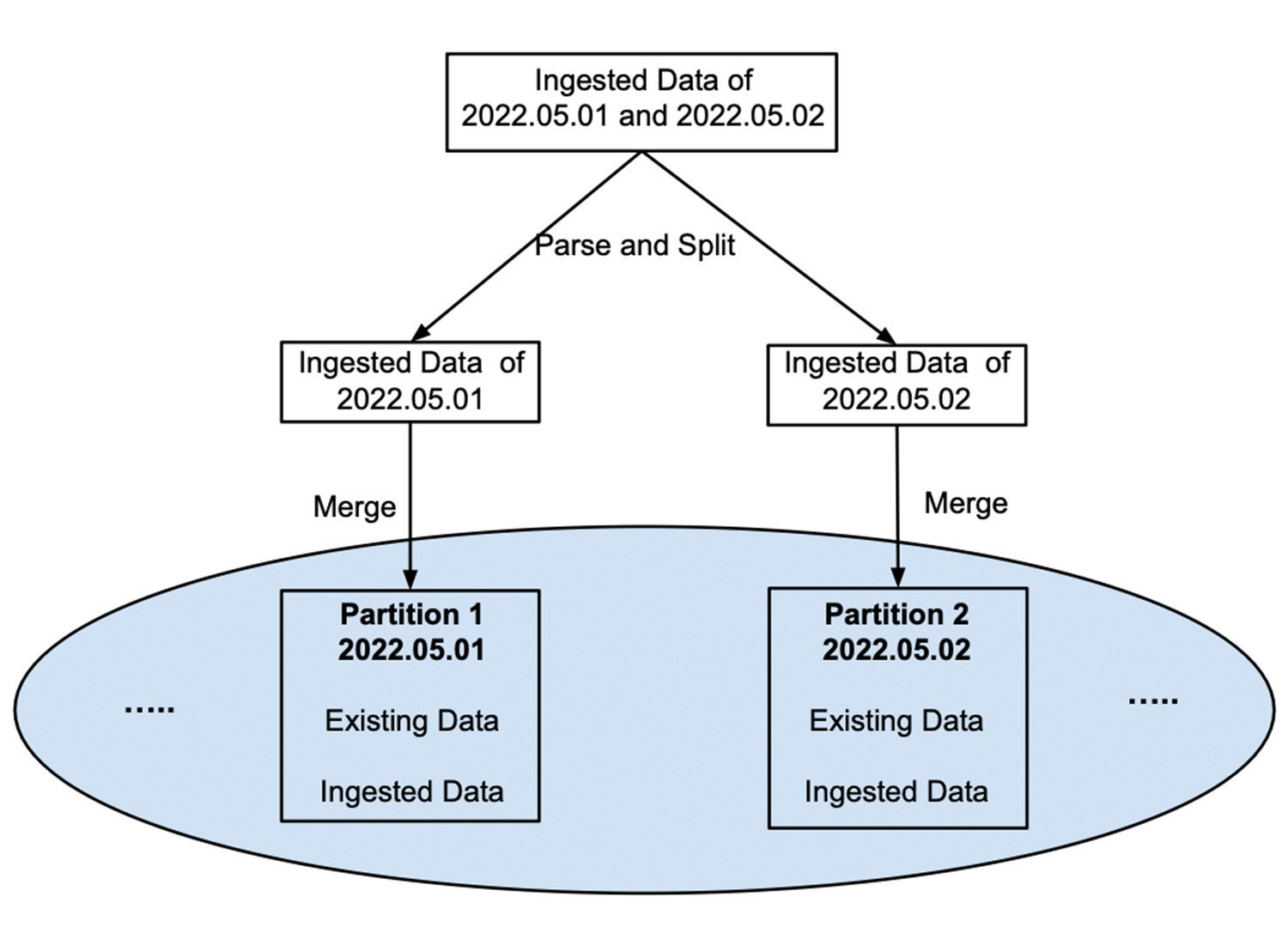
Naive Ingestion. To stay the information of a partition in a record for the advantages of studying optimization famous above, each and every time a collection of knowledge is ingested, it will have to be parsed and cut up into the suitable walls, then merged into the prevailing record of its corresponding partition, as illustrated in Determine 3.
The method of merging new information with current information regularly takes time as a result of pricey I/O and the price of blending and encoding the information of the partition. This may occasionally result in lengthy latency for responses again to the buyer that the information is effectively ingested, and for queries of the newly ingested information, as it is going to no longer in an instant be to be had in garage.
 InfluxData
InfluxDataDetermine 3: Naive ingestion through which new information is merged into the similar record as current information in an instant.
Low latency ingestion. To stay the latency of every ingestion low, we will cut up the method into two steps: ingestion and compaction.
Ingestion
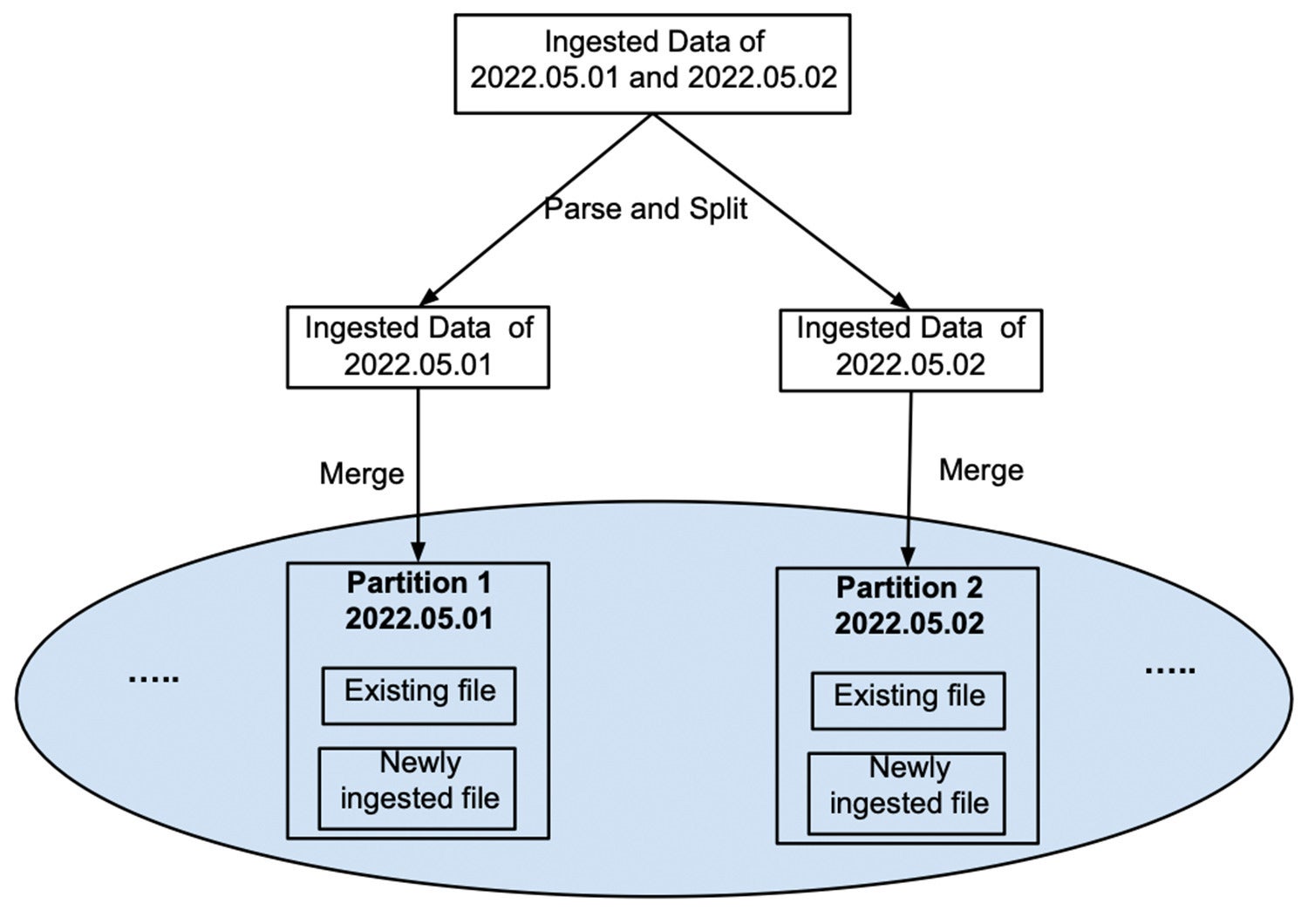
All the way through the ingestion step, ingested information is divided and written to its personal record as proven in Determine 4. It isn’t merged with the prevailing information of the partition. As quickly because the ingested information is effectively sturdy, the ingest shopper will obtain a good fortune sign and the newly ingested record will likely be to be had for querying.
If the ingest price is prime, many small information will collect within the partition, as illustrated in Determine 5. At this level, a question that wishes information from a partition will have to learn the entire information of that partition. This in fact isn’t excellent for question functionality. The compaction step, described under, helps to keep this accumulation of information to a minimal.
 InfluxData
InfluxDataDetermine 4: Newly ingested information is written into a brand new record.
 InfluxData
InfluxDataDetermine 5: Underneath a prime ingest workload a partition will collect many information.
Compaction
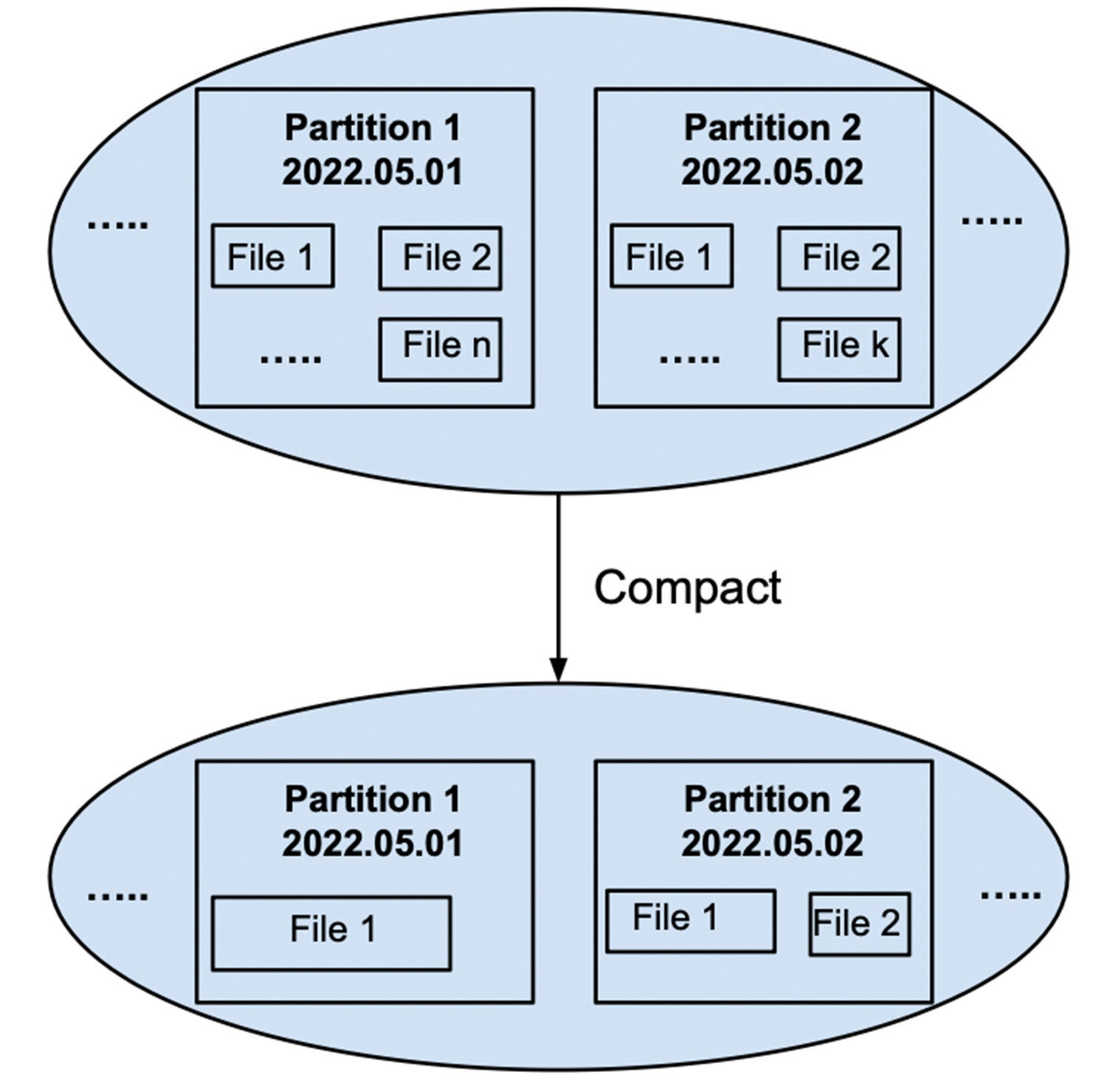
Compaction is the method of merging the information of a partition into one or a couple of information for higher question functionality and compression. For instance, Determine 6 presentations the entire information in partition 2022.05.01 being merged into one record, and the entire information of partition 2022.05.02 being merged into two information, every smaller than 100MB.
The selections relating to how regularly to compact and the utmost measurement of compacted information will likely be other for various techniques, however the not unusual objective is to stay the question functionality prime via lowering I/Os (i.e., the choice of information) and having the information big enough to successfully compress.
 InfluxData
InfluxDataDetermine 6: Compacting a number of information of a partition into one or few information.
Sizzling vs. chilly walls
Walls which can be queried regularly are thought to be scorching walls, whilst the ones which can be hardly ever learn are known as chilly walls. In databases, scorching walls are typically the walls containing contemporary information similar to contemporary gross sales dates. Chilly walls regularly include older information, that are much less prone to be learn.
Additionally, when the information will get outdated, it’s typically queried in higher chunks similar to via month and even via yr. Listed below are a couple of examples to unambiguously categorize information from scorching to chilly:
- Sizzling: Information from the present week.
- Much less scorching: Information from earlier weeks however within the present month.
- Chilly: Information from earlier months however within the present yr.
- Extra chilly: Information of remaining yr and older.
To scale back the anomaly between cold and warm information, we wish to in finding solutions to 2 questions. First, we wish to quantify scorching, much less scorching, chilly, extra chilly, and maybe even increasingly more chilly. 2nd, we wish to believe how we will reach fewer I/Os in relation to studying chilly information. We don’t need to learn 365 information, every representing a one-day partition of knowledge, simply to get remaining yr’s gross sales earnings.
Hierarchical partitioning
Hierarchical partitioning, illustrated in Determine 7, supplies solutions to the 2 questions above. Information for on a daily basis of the present week is saved in its personal partition. Information from earlier weeks of the present month are partitioned via week. Information from prior months within the present yr are partitioned via month. Information this is even older is partitioned via yr.
This style may also be comfortable via defining an energetic partition instead of the present date partition. All information arriving after the energetic partition will likely be partitioned via date, while information prior to the energetic partition will likely be partitioned via week, month, and yr. This permits the formula to stay as many small contemporary walls as vital. Despite the fact that all examples on this put up partition information via time, non-time partitioning will paintings in a similar way so long as you’ll outline expressions for a partition and their hierarchy.
 InfluxData
InfluxDataDetermine 7: Hierarchical partitioning.
Hierarchical partitioning reduces the choice of walls within the formula, making it more uncomplicated to regulate, and lowering the choice of walls that wish to be learn when querying higher and older chunks.
The question procedure for hierarchical partitioning is equal to for non-hierarchical partitioning, as it is going to follow the similar pruning solution to learn most effective the related walls. The ingestion and compaction processes will likely be a bit of extra sophisticated, as it is going to be harder to arrange the walls of their outlined hierarchy.
Mixture partitioning
Many organizations don’t need to stay outdated information, however choose as a substitute to stay aggregations similar to choice of orders and general gross sales of each and every product each and every month. This may also be supported via aggregating information and partitioning them via month. On the other hand, for the reason that combination walls retailer aggregated information, their schema will likely be other from non-aggregated walls, which is able to result in additional paintings for consuming and querying. There are alternative ways to regulate this chilly and aggregated information, however they’re huge subjects appropriate for a long run put up.
Nga Tran is a personnel instrument engineer at InfluxData, and a member of the InfluxDB IOx crew, which is construction the next-generation time collection garage engine for InfluxDB. Sooner than InfluxData, Nga have been with Vertica Analytic DBMS for over a decade. She used to be one of the vital key engineers who constructed the question optimizer for Vertica, and later, ran Vertica’s engineering crew.
—
New Tech Discussion board supplies a venue to discover and speak about rising endeavor generation in extraordinary intensity and breadth. The choice is subjective, in response to our pick out of the applied sciences we imagine to be essential and of biggest hobby to InfoWorld readers. InfoWorld does no longer settle for advertising collateral for e-newsletter and reserves the suitable to edit all contributed content material. Ship all questions to [email protected].
Copyright © 2022 IDG Communications, Inc.
Supply By way of https://www.infoworld.com/article/3666513/partitioning-for-performance-in-a-sharding-database-system.html
