
Each records warehouses and information lakes can dangle massive quantities of information for research. As you could recall, records warehouses comprise curated, structured records, have a predesigned schema this is carried out when the information is written, name on massive quantities of CPU, SSDs, and RAM for velocity, and are meant to be used by way of industry analysts. Information lakes dangle much more records that may be unstructured or structured, to begin with saved uncooked and in its local layout, most often use reasonable spinning disks, observe schemas when the information is learn, clear out and develop into the uncooked records for research, and are meant to be used by way of records engineers and information scientists to begin with, with industry analysts ready to make use of the information as soon as it’s been curated..
Information lakehouses, corresponding to the topic of this assessment, Dremio, bridge the distance between records warehouses and information lakes. They begin with a knowledge lake and upload immediate SQL, a extra environment friendly columnar garage layout, a knowledge catalog, and analytics.
Dremio describes its product as a knowledge lakehouse platform for groups that know and love SQL. Its promoting issues are
- SQL for everybody, from industry person to records engineer;
- Absolutely controlled, with minimum device and information repairs;
- Fortify for any records, being able to ingest records into the lakehouse or question in position; and
- No lock-in, with the versatility to make use of any engine lately and day after today.
In line with Dremio, cloud records warehouses corresponding to Snowflake, Azure Synapse, and Amazon Redshift generate lock-in since the records is within the warehouse. I don’t utterly trust this, however I do agree that it’s in point of fact onerous to transport massive quantities of information from one cloud gadget to some other.
Additionally consistent with Dremio, cloud records lakes corresponding to Dremio and Spark be offering extra flexibility because the records is saved the place more than one engines can use it. That’s true. Dremio claims 3 benefits that derive from this:
- Flexibility to make use of more than one best-of-breed engines at the identical records and use instances;
- Simple to undertake further engines lately; and
- Simple to undertake new engines someday, merely level them on the records.
Competition to Dremio come with the Databricks Lakehouse Platform, Ahana Presto, Trino (previously Presto SQL), Amazon Athena, and open-source Apache Spark. Much less direct competition are records warehouses that fortify exterior tables, corresponding to Snowflake and Azure Synapse.
Dremio has painted all undertaking records warehouses as their competition, however I brush aside that as advertising, if no longer precise hype. Finally, records lakes and information warehouses satisfy other use instances and serve other customers, although records lakehouses a minimum of partly span the 2 classes.
Dremio Cloud evaluation
Dremio server device is a Java records lakehouse utility for Linux that may be deployed on Kubernetes clusters, AWS, and Azure. Dremio Cloud is mainly the Dremio server device working as an absolutely controlled provider on AWS.
Dremio Cloud’s purposes are divided between digital personal clouds (VPCs), Dremio’s and yours, as proven within the diagram beneath. Dremio’s VPC acts because the keep an eye on airplane. Your VPC acts as an execution airplane. When you use more than one cloud accounts with Dremio Cloud, every VPC acts as an execution airplane.
The execution airplane holds more than one clusters, referred to as compute engines. The keep an eye on airplane processes SQL queries with the Sonar question engine and sends them via an engine supervisor, which dispatches them to an acceptable compute engine in line with your regulations.
Dremio claims sub-second reaction occasions with “reflections,” that are optimized materializations of supply records or queries, very similar to materialized perspectives. Dremio claims uncooked velocity that’s 3x sooner than Trino (an implementation of the Presto SQL engine) due to Apache Arrow, a standardized column-oriented reminiscence layout. Dremio additionally claims, with out specifying some extent of comparability, that records engineers can ingest, develop into, and provision records in a fragment of the time due to SQL DML, dbt, and Dremio’s semantic layer.
Dremio has no industry intelligence, device finding out, or deep finding out features of its personal, however it has drivers and connectors that fortify BI, ML, and DL device, corresponding to Tableau, Energy BI, and Jupyter Notebooks. It may well additionally connect with records resources in tables in lakehouse garage and in exterior relational databases.
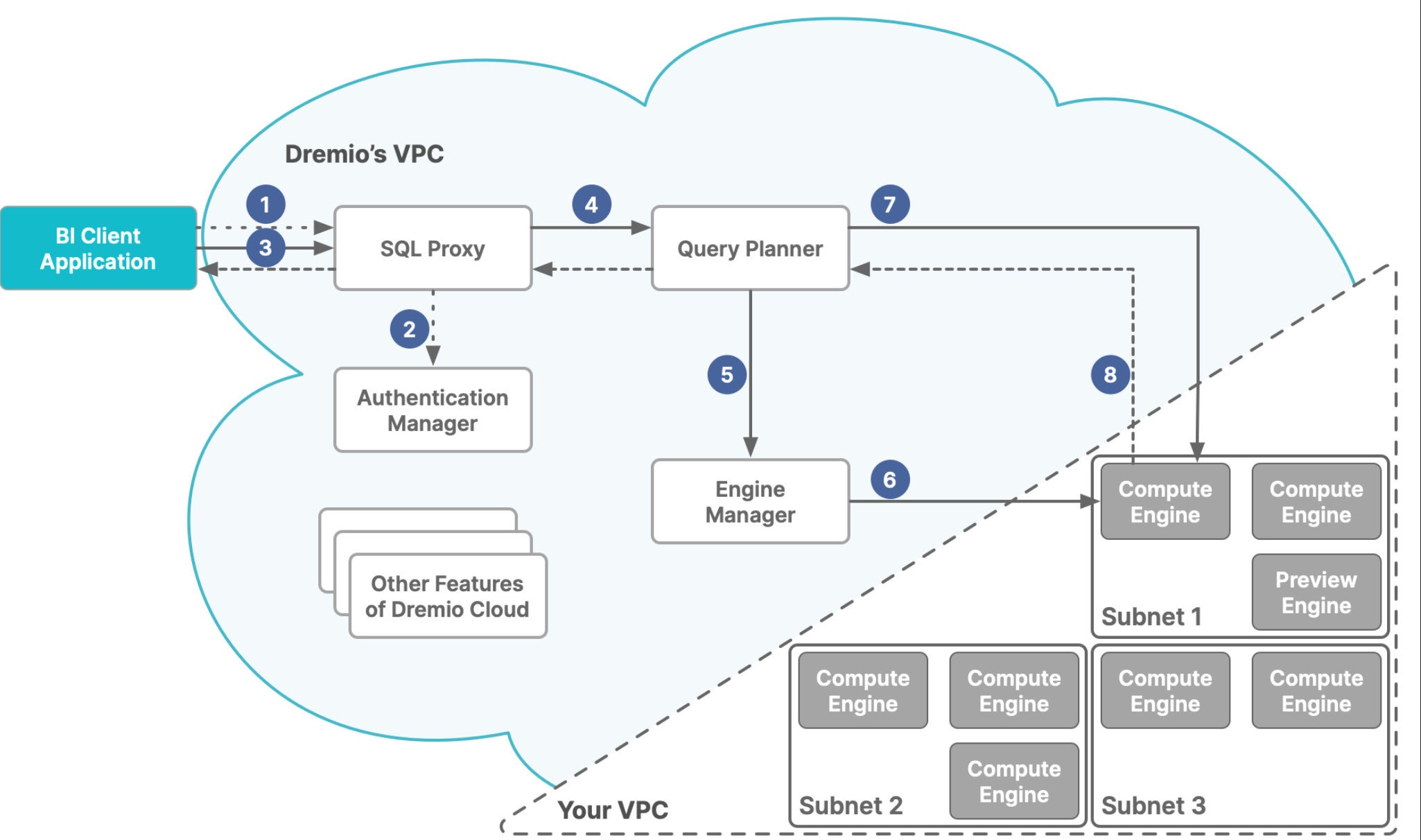 IDG
IDGDremio Cloud is divided into two Amazon digital personal clouds (VPCs). Dremio’s VPC hosts the keep an eye on airplane, together with the SQL processing. Your VPC hosts the execution airplane, which accommodates the compute engines.
Dremio Arctic evaluation
Dremio Arctic is an clever metastore for Apache Iceberg, an open desk layout for enormous analytic datasets, powered by way of Nessie, a local Apache Iceberg catalog. Arctic supplies a contemporary, cloud-native choice to Hive Metastore, and is supplied by way of Dremio as a forever-free provider. Arctic provides the next features:
- Git-like records control: Brings Git-like model keep an eye on to records lakes, enabling records engineers to regulate the information lake with the similar superb practices Git permits for device construction, together with commits, tags, and branches.
- Information optimization (coming quickly): Robotically maintains and optimizes records to permit sooner processing and cut back the guide effort fascinated by managing a lake. This contains making sure that the information is columnarized, compressed, compacted (for higher recordsdata), and partitioned accurately when records and schemas are up to date.
- Works with all engines: Helps all Apache Iceberg-compatible applied sciences, together with question engines (Dremio Sonar, Presto, Trino, Hive), processing engines (Spark), and streaming engines (Flink).
Dremio records record codecs
A lot of the functionality and capability of Dremio relies on the disk and reminiscence records record codecs used.
Apache Arrow
Apache Arrow, which was once created by way of Dremio and contributed to open supply, defines a language-independent columnar reminiscence layout for flat and hierarchical records, arranged for environment friendly analytic operations on fashionable {hardware} like CPUs and GPUs. The Arrow reminiscence layout additionally helps zero-copy reads for lightning-fast records get admission to with out serialization overhead.
Gandiva is an LLVM-based vectorized execution engine for Apache Arrow. Arrow Flight implements RPC (faraway process calls) on Apache Arrow, and is constructed on gRPC. gRPC is a contemporary, open-source, high-performance RPC framework from Google that may run in any surroundings; gRPC is most often 7x to 10x sooner than REST message transmission.
Apache Iceberg
Apache Iceberg is a high-performance layout for enormous analytic tables. Iceberg brings the reliability and straightforwardness of SQL tables to special records, whilst making it imaginable for engines corresponding to Sonar, Spark, Trino, Flink, Presto, Hive, and Impala to securely paintings with the similar tables, on the identical time. Iceberg helps bendy SQL instructions to merge new records, replace current rows, and carry out centered deletes.
Apache Parquet
Apache Parquet is an open-source, column-oriented records record layout designed for environment friendly records garage and retrieval. It supplies environment friendly records compression and encoding schemes with enhanced functionality to care for complicated records in bulk.
Apache Iceberg vs. Delta Lake
In line with Dremio, the Apache Iceberg records record layout was once created by way of Netflix, Apple, and different tech powerhouses, helps INSERT/UPDATE/DELETE with any engine, and has sturdy momentum within the open-source group. Against this, once more consistent with Dremio, the Delta Lake records record layout was once created by way of Databricks, and when working on Databricks’ platform on AWS, helps INSERT/UPDATE with Spark and SELECT with any SQL question engine.
Dremio issues out a very powerful technical distinction between the open supply model of Delta Lake and the model of Delta Lake that runs at the Databricks platform on AWS. As an example, there’s a connector that permits Trino to learn and write open supply Delta Lake recordsdata, and a library that permits Scala and Java-based tasks (together with Apache Flink, Apache Hive, Apache Beam, and PrestoDB) to learn from and write to open supply Delta Lake. Alternatively, those equipment can not safely write to Delta Lake recordsdata on Databricks’ platform on AWS.
Dremio question acceleration
Along with the question functionality this is derived from the record codecs used, Dremio can boost up queries the usage of a columnar cloud cache and information reflections.
Columnar Cloud Cache (C3)
Columnar Cloud Cache (C3) permits Dremio to reach NVMe-level I/O functionality on Amazon S3, Azure Information Lake Garage, and Google Cloud Garage by way of the usage of the NVMe/SSD constructed into cloud compute circumstances, corresponding to Amazon EC2 and Azure Digital Machines. C3 best caches records required to fulfill your workloads and will also cache person microblocks inside datasets. In case your desk has 1,000 columns and also you best question a subset of the ones columns and clear out for records inside a undeniable time-frame, then C3 will cache best that portion of your desk. By means of selectively caching records, C3 additionally dramatically reduces cloud garage I/O prices, which may make up 10% to fifteen% of the prices for every question you run, consistent with Dremio.
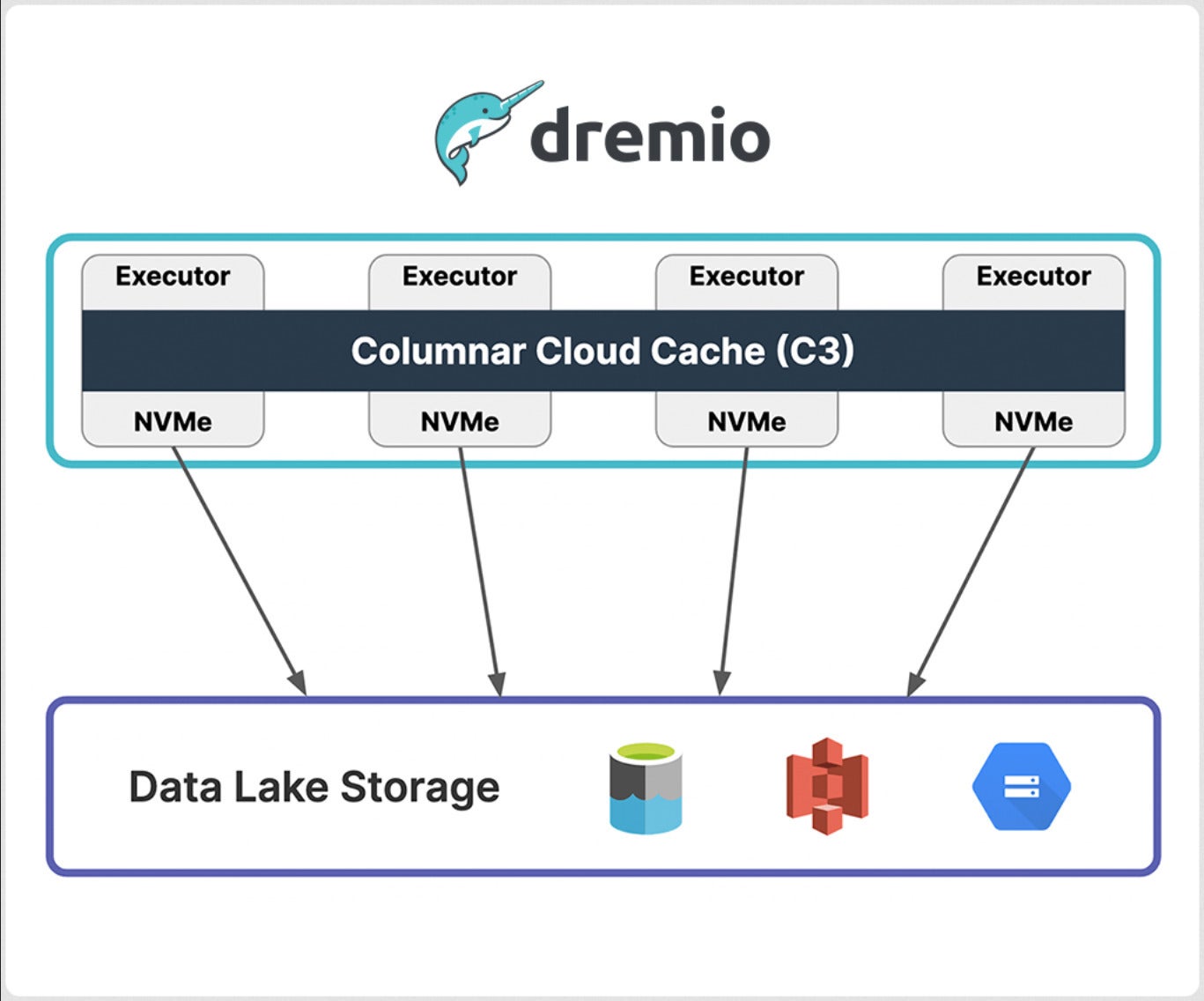 IDG
IDGDremio’s Columnar Cloud Cache (C3) characteristic speeds up long run queries by way of the usage of the NVMe SSDs in cloud circumstances to cache records utilized by earlier queries.
Information Reflections
Information Reflections permit sub-second BI queries and do away with the want to create cubes and rollups previous to research. Information Reflections are records buildings that intelligently precompute aggregations and different operations on records, so that you don’t need to do complicated aggregations and drill-downs at the fly. Reflections are utterly clear to finish customers. As an alternative of connecting to a selected materialization, customers question the required tables and perspectives and the Dremio optimizer selections the most efficient reflections to fulfill and boost up the question.
Dremio Engines
Dremio includes a multi-engine structure, so you’ll create more than one right-sized, bodily remoted engines for quite a lot of workloads for your group. You’ll simply arrange workload control regulations to direction queries to the engines you outline, so that you’ll by no means have to fret once more about complicated records science workloads fighting an govt’s dashboard from loading. With the exception of getting rid of useful resource rivalry, engines can temporarily resize to take on workloads of any concurrency and throughput, and auto-stop while you’re no longer working queries.
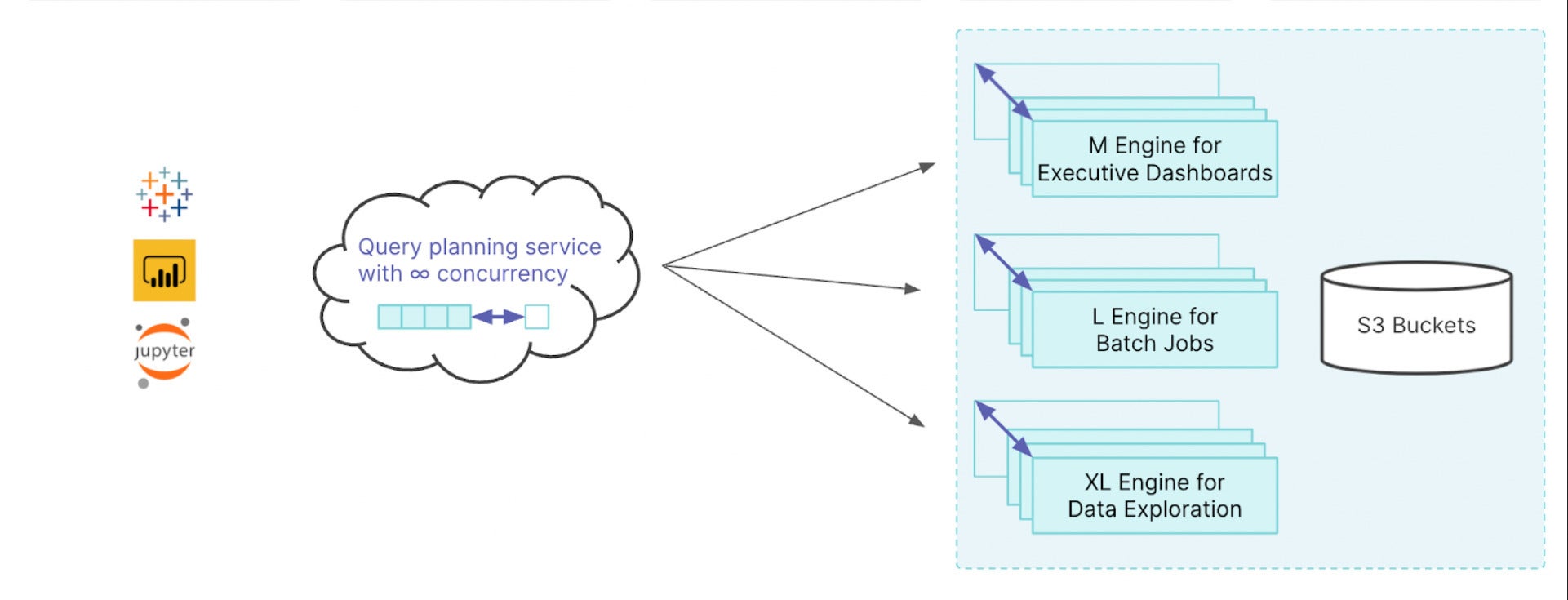 IDG
IDGDremio Engines are necessarily scalable clusters of circumstances configured as executors. Regulations lend a hand to dispatch queries to the required engines.
Getting began with Dremio Cloud
The Dremio Cloud Getting Began information covers
- Including a knowledge lake to a mission;
- Making a bodily dataset from supply records;
- Making a digital dataset;
- Querying a digital dataset; and
- Accelerating a question with a mirrored image.
I received’t display you each step of the educational, since you’ll learn it your self and run via it in your personal unfastened account.
Two crucial issues are that:
- A bodily dataset (PDS) is a desk illustration of the information for your supply. A PDS can’t be changed by way of Dremio Cloud. The best way to create a bodily dataset is to layout a record or folder as a PDS.
- A digital dataset (VDS) is a view derived from bodily datasets or different digital datasets. Digital datasets aren’t copies of the information so that they use little or no reminiscence and all the time mirror the present state of the father or mother datasets they’re derived from.
Supply By means of https://www.infoworld.com/article/3671872/dremio-cloud-review-a-fast-and-flexible-data-lakehouse-on-aws.html
